Georeactor Blog
RSS FeedIgnore Previous Instructions and 𝑥
I'm reworking the "Chat-OMG" and "Comments / Criticism" sections of "ML Arxiv Haul" into this new series.
As we enter 2024, AI research is in the hands of a somewhat small research elite and a competitive mass of smaller labs and startups. This leads to absurdities such as the GPT-4 and Gemini white papers explaining little (not even number of parameters), dataset-centric papers failing to share the data, and researchers picking the evaluations to look a few points over their competitors.
Andrej Karpathy, an influential researcher at OpenAI and formerly at Tesla, warns:
I pretty much only trust two LLM evals right now: Chatbot Arena and r/LocalLlama comments section
Meanwhile generative AI startups are getting…. weirder? Scarier? Hall of Shame here:
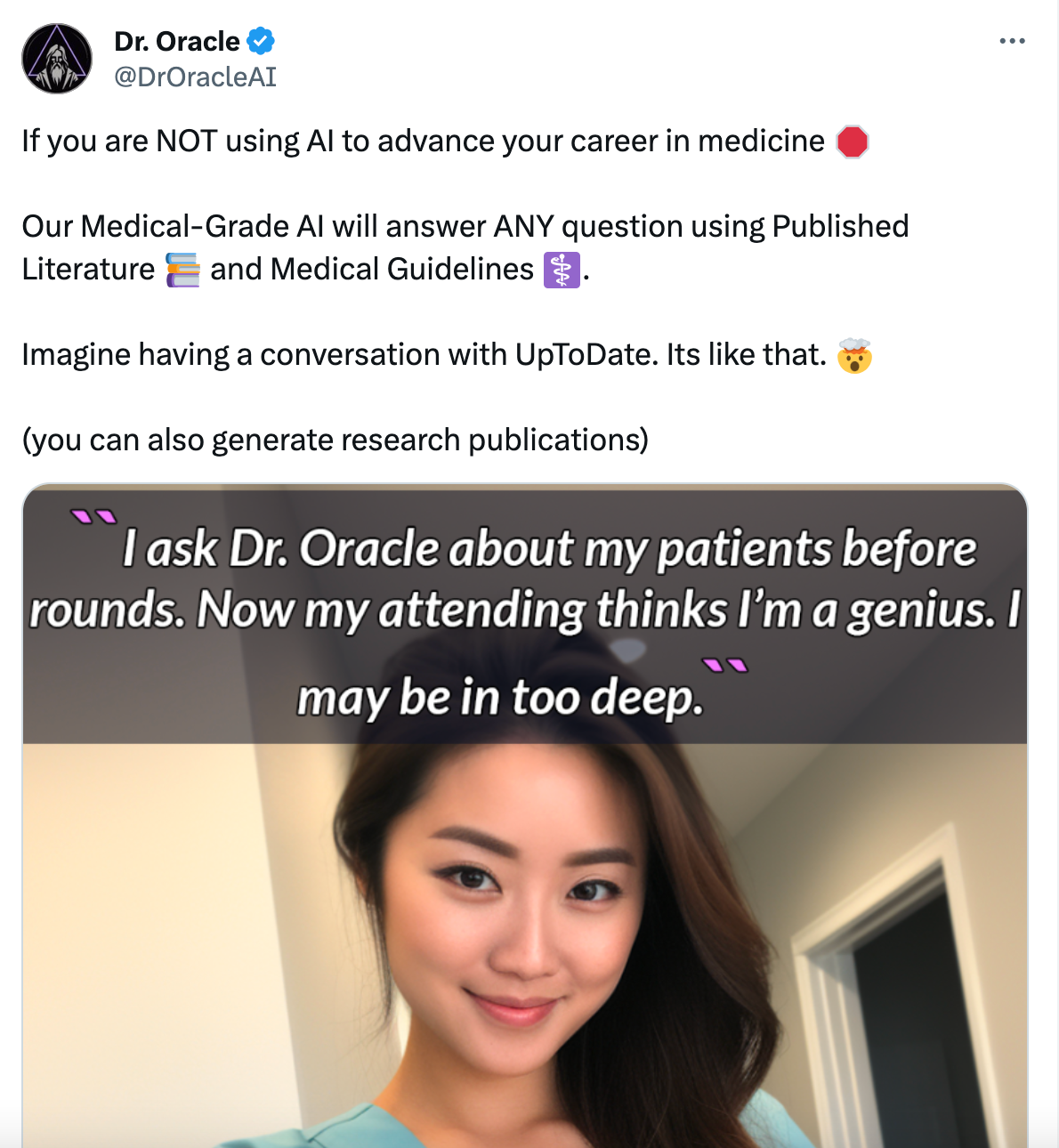
Is this all a bleak outlook for research, or a chance for Transformers and LangChain to bring more engineers and hackers into the space?
Topical Issue: the Decline Effect
A simmering trend of 2023 was OpenAI models' degrading quality. At first the discussion was focused on politics, but in July a pre-print showed that models were also getting worse at identifying prime numbers and generating code. Now I hear that models quibble or explain the work rather than doing the actual task. The Anthropic AI agent Claude has faced similar criticism (but this might be a totally new model).
I have theories for this, none of them provable due to lack of transparency.
- maintenance: OpenAI continues training their model on new text to advance the cutoff date. This process produces a model which just happens to be worse, or they haven't solved the problem of catastrophic forgetting.
- scaling: in response to traffic, OpenAI experiments with pruning, speculative execution, or adapter layer math in a way which lowers performance, but fits OpenAI's requirements
- misalignment: by training on ChatGPT edge cases around what an assistant can't do / doesn't know / shouldn't answer, the model learns helplessness.
- eating ham: it's rumored that ChatGPT's "secret sauce" is synthetic text (similar to Microsoft's Phi models). When trained on human text from the web, quality degrades.
- eating spam: the opposite of previous point - by continuing training on AI outputs, negativity about AI, and generated text on the web, there is some kind of productive but narrow intelligence effect of AI-to-AI alignment? This vibes well with a discovery that X/Grok believes it is an OpenAI agent, and that Mixtral performs better on evaluations when pretending to be OpenAI.
- dark horse: something wholly unexpected from 'models leak info or tone across batches' to 'training meta-learned to expend less energy on responses' to 'cosmic rays and GPUs' to 'contact with the Jungian unconscious'.
In the Hot Seat
On Dec 12, Peter Henderson pointed to likely hallucinated citations in Michael Cohen's legal case; this was confirmed on Dec 29th
Negotiating car sale price with a GPT
Uber Eats might be generating (poorly thought-out) images for menus.
A film concept artist uses Midjourney's newest model to regenerate Marvel IP from training data, gets banned
Can ChatGPT be swayed with promised 'tips and threats'?
Observed variation in responses based on dates in ChatGPT's prompt; plus someone said it gets worked up around the holidays (?)
After ChatGPT was caught answering questions about GPT-4.5, an OpenAI engineer could only describe it as "a very weird and oddly consistent hallucination". Hacker News suggested that an internal GPT-4.5 was being used to RLHF-tune GPT-4? But no one really knows.
I'm OK with this
After users compared LLMs' cookie and muffin recipes, suggestion for more global taste tests
The DROP evaluation got rejected because the answers are parsed strangely: https://huggingface.co/blog/leaderboard-drop-dive
Peak Argentina? https://twitter.com/jajandio/status/1729343675933577440
Toward the end of a new 'Bankrupt' video, they complain about Six Flags / Cedar Fair prominently using AI-generated images in a merger presentation. My best guess is that the merger teams either didn't want to feature one company's assets over another, that they had a limited budget / staff who were walled off from other teams, or that the slides go through some consultant or outsourcing. Who knows?