Georeactor Blog
RSS FeedFine-tuning savvy LLMs
Now that LLaMa v2 weights are available with a license agreement, development on Vicuña and other models updated.
LangChain and LLaMa v2
I used LangChain with a LLaMa chat-tuned model, even though the library docs are insistently OpenAI.
The key appears to be using the basic ConversationChain class, and a custom prompt to match how LLaMa was trained: https://gist.github.com/mapmeld/782186ad1acadb3642fd105f9f777759
HuggingFace has a blog which includes the correct instruction prompting format: https://huggingface.co/blog/llama2#how-to-prompt-llama-2 If you leave out the prompt, LLaMa will continue generating a pretend conversation between human and AI agent, instead of waiting for your next message.
The memory should probably be a longer number of tokens than in the example. I'm not sure that it's currently in the right place in the prompt.
If you have a set of documents as the basis, you should use LangChain's ConversationalRetrievalChain.
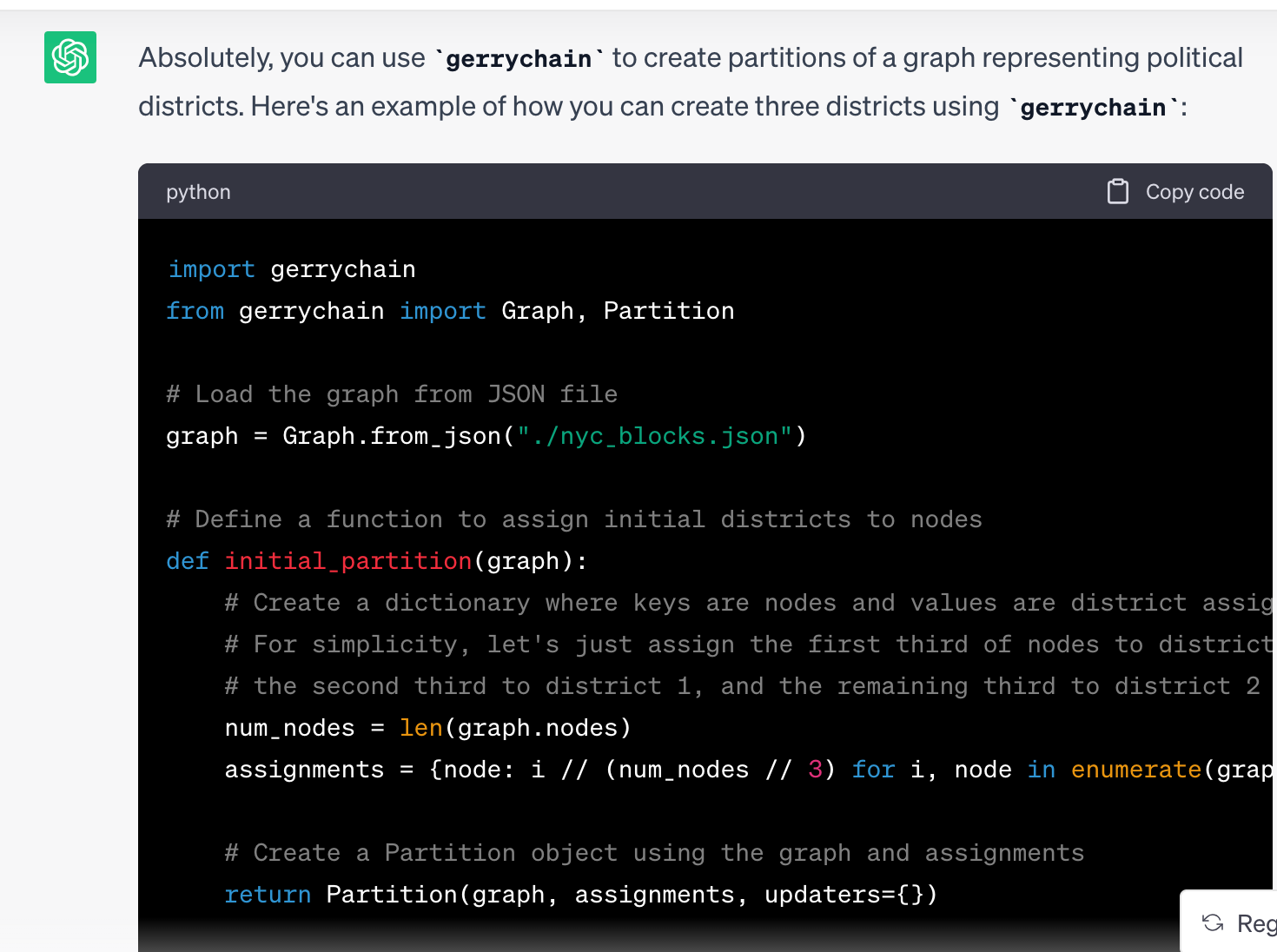
My idea was for the model to use the GerryChain library to interact with an election precinct shapefile. The whole map cannot easily be vectorized or converted to in-context text, so this would work something like a retrieval model or AgentGPT. The LLM would have iterative rounds of querying the graph, making permutations, collecting statistics, until it got to a satisfactory end point. This appears to be beyond LLaMa v2 7B Chat; it wants to discuss the project but does not know the GerryChain library or write code. I've seen other comments about difficulties in getting LLaMa to generate code, so I would probably want to start with a fine-tuned model.
ChatGPT-3.5 knows about GerryChain and generated some valid code. It still takes a lot more work to put an LLM in active and iterative role (try offering to help ChatGPT access the internet by searching and running cURL commands for it, total non-starter).
More likely I should get a basic starter graph and find prompts which get the LLM to do commands and draw something interesting. Here ChatGPT generated GerryChain code without any code prompting, but it doesn't give us a starting point for meaningful assignments.
QLoRA
Another current trend is to make training easier on a smaller GPU using parameter-efficient fine-tuning (PEFT). Typically this is the LoRA method or combined with quantization: QLoRA. The QLoRA repo already has a LLaMa v2 example, using an instruction-tuning dataset to make an model named after a wild llama (Guanaco) https://github.com/artidoro/qlora/blob/main/scripts/finetune_llama2_guanaco_7b.sh
For some reason the example script uses an OpenAssistant dataset and not the purported original multilingual Guanaco dataset. So is this output model a true Guanaco? Anyway here are both dataset links:
- https://huggingface.co/datasets/OpenAssistant/oasst1
- https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
The script ran fairly quickly on CoLab.
I'd like to try models with my own datasets - Reddit one-ups, AskNYC, and a potential geospatial coding problem set.