Georeactor Blog
RSS FeedML Arxiv Haul #23
Comments / Criticism
- Skepticism over whether HumanEval is that good to be used as a test of code LLMs: https://www.reddit.com/r/LocalLLaMA/comments/161waft/humaneval_as_an_accurate_code_benchmark/
- Most citations go to the wrong (i.e. not original) ReLU paper: https://www.reddit.com/r/MachineLearning/comments/167n0g0/d_am_i_the_only_one_finding_this_a_bit_upsetting/
- Analysis of an AI content farm: https://twitter.com/FeryKaszoni/status/1704241895616979093
- Not sure of the causality logic here, but an argument that tools which make it easier to write and distribute longer texts increase length of books, laws, regulations, etc: https://twitter.com/bernhardsson/status/1705051188440207693
- The Linux Foundation adopted RWKV, a return to RNNs to overtake transformer models, as their first language model project https://lfaidata.foundation/blog/2023/09/21/lf-ai-data-launches-generative-ai-commons/
- Relevant to my interests, an upcoming project to have geospatial coding model benchmarks: https://twitter.com/STKO_UCSB/status/1697299575487250707
Chat-O.M.G.
A former colleague wrote an essay after an Iowa school used ChatGPT to pick which books contained inappropriate content. https://galecia.com/blogs/jim-craner/missing-point-iowa-ai-book-banning-brouhaha
I was looking for an old political article suggesting that Trump's misspeaking about hurricanes and other topics was just from being nearsighted. Google suggested this oddly specific domain, article, and quote, which turned out to be from a ChatGPT generation:
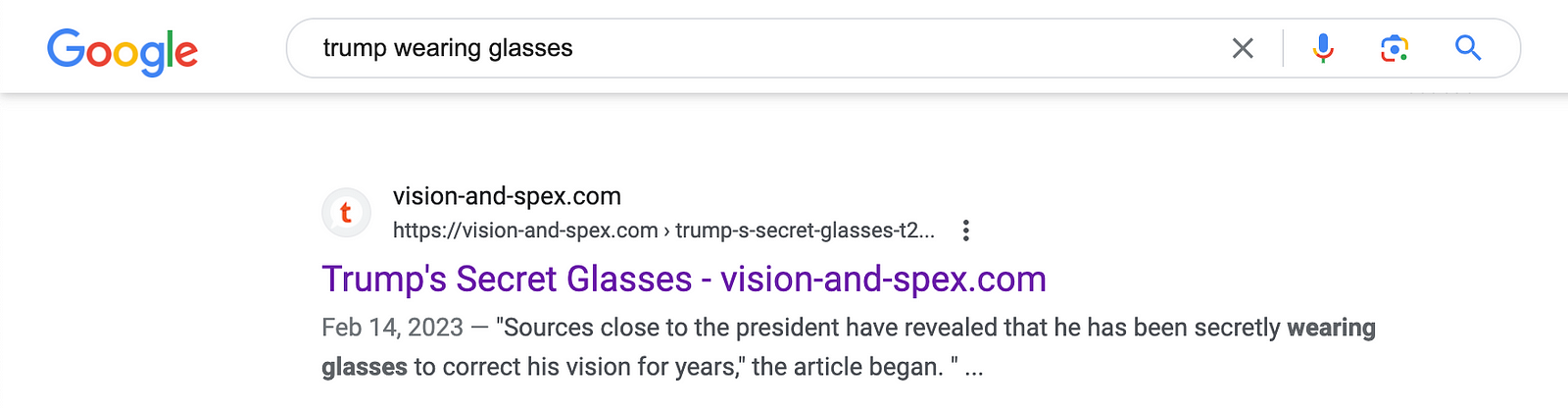
- Similarly Quora and their wildly successful SEO has gotten their ChatGPT experiments high up into Google search and 'one box' type answers: https://twitter.com/TylerGlaiel/status/1706395577964208395
Papers
A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models
Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. However, these…
Johns Hopkins and Microsoft researchers fine-tune an LLM on translation tasks, which have otherwise been lagging behind encoder-decoder models.
AI Deception: A Survey of Examples, Risks, and Potential Solutions - LessWrong
By Peter S. Park, Simon Goldstein, Aidan O'Gara, Michael Chen, and Dan Hendrycks ...
The effective altruists over at LessWrong have been building a list of AI models behaving badly and covering up for themselves, such as GPT-4's famous deception to solve a CAPTCHA.
One puzzling anecdote is Meta's Diplomacy game agent, which was publicly promoted as truthful, but is described as "… an expert liar. It not only betrayed other players, but also engaged in premeditated deception, planning in advance to build a fake alliance…". This may be subjectivity of whether AI is deceptive?
mrwadams/attackgen
AttackGen is a cybersecurity incident response testing tool that leverages the power of large language models and the…
Writes cybersecurity tabletop scenarios customized to your business and common system architectures.
BHASA: A Holistic Southeast Asian Linguistic and Cultural Evaluation Suite for Large Language Models
The rapid development of Large Language Models (LLMs) and the emergence of novel abilities with scale have necessitated…
AI Singapore has developed a benchmark in Indonesian, Vietnamese, Thai, and Tamil languages. In addition to collecting common tasks, there are some cultural knowledge questions. LLMs seemed particularly poor at Tamil tasks. On their GitHub, they've only released the initial Indonesian dataset, including 33 cultural questions.
From a linguistics perspective, it's interesting that the paper does not discuss Indonesian and Malay as language identifiers, nor does it mention Lao.
BioCoder: A Benchmark for Bioinformatics Code Generation with Contextual Pragmatic Knowledge
Pre-trained language models like ChatGPT have significantly improved code generation. As these models scale up, there…
Testing models' capabilities at generating code for common bioinformatics purposes, in Python and Java.
Building Chat LangChain
Beyond conventional library docs, LangChain is going to deploy a chatbot to explain LangChain! They are doing retrieval with OpenAI embeddings stored in a Weaviate vector store / db.
Section says that they eventually decided not to index the code for this search tool.
Chain-of-Verification Reduces Hallucination in Large Language Models
Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language…
Meta's strategy to generate an answer (such as: a list of politicians born in New York), pull factual questions out of that answer, and then ask itself about those individual facts or associations before outputting a final checked answer. This could help with a particular type of hallucination where the model does know the 'correct' answer and is just compelled to hallucinate, in this example similar people in the same list.
CityDreamer: Compositional Generative Model of Unbounded 3D Cities
In recent years, extensive research has focused on 3D natural scene generation, but the domain of 3D city generation…
Paper collected 3D imagery from Google Earth and streets (+ building heights) from OpenStreetMap to generate new cities, much more accurate than an off-the-shelf GAN.
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation
In recent years, extensive research has focused on 3D natural scene generation, but the domain of 3D city generation…
HumanEval is a popular code-generation benchmark, but generally has smaller problems and single-function code samples. ClassEval, from Fudan University, has 100 tasks with class-level code generation tasks, in Python.
Dolma: 3 Trillion Token Open Corpus for Language Model Pretraining
We released Dolma, OLMo's pretraining dataset. Dolma open dataset of 3 trillion tokens. Available on HuggingFace under…
There seem to be a trend of open curated corpora releases, here's AllenAI's.
The Google / DeepMind one is called MADLAD-400: https://arxiv.org/abs/2309.04662
Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve
The widespread adoption of large language models (LLMs) makes it important to recognize their strengths and…
Lots of text here, but for straightforward language manipulation tasks (reversal, sorting, pig Latin) the GPT models were significantly more likely to have errors if the output word sequence would be low probability in a standard generation. This means fine-tuning / instructions / etc. is still not overcoming tasks which are just language manipulation.
ExpertQA: Expert-Curated Questions and Attributed Answers
As language models are adapted by a more sophisticated and diverse set of users, the importance of guaranteeing that…
2,177 questions provided by experts in various fields.
This is a high-quality dataset and all, but I don't have a lot to say and included it to have 23 items in the 23rd Arxiv haul, even though two of these have links to uncounted papers and three of them aren't very on topic. Who knows, it's getting too meta-referential now.
From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting
Selecting the 'right' amount of information to include in a summary is a difficult task. A good summary should be…
Fine-tunes a model on a summary task with a series of increasingly information-dense paragraphs.
HyenaDNA: learning from DNA with 1 Million token context
HyenaDNA is a long genomic sequence model trained on the Human Reference Genome with context length of up to 1 million…
Unlike the amino acid-level token LLM work that I looked at before, Hyena uses four nucleotide tokens plus some control characters. The team did a great deal of work, described here, to extend the context window (context: each chromosome has 50–250 million base pairs). The concerns are different from typical LLMs so I don't know if it's applicable to other models, or if they would rather use rotational encoding here?
Intriguing Properties of Quantization at Scale
Emergent properties have been widely adopted as a term to describe behavior not present in smaller models but observed…
Cohere looking for properties of successfully quantized models.
kaganisildak/malwarescarecrow
A tool designed to make physical devices detectable by malware and make system look like virtual machine.
Not super ML, but something clever which came up in a SwiftOnSecurity thread. They suggested that the best security would be from making your servers look like honeypot / malware testing boxes, dissuading attackers. Someone replied with this actual tool, which is light on documentation but falls into this category.
OctoPack: Instruction Tuning Code Large Language Models
Finetuning large language models (LLMs) on instructions leads to vast performance improvements on natural language…
Instruction code model OctoCoder from Big Code Project / HuggingFace. Includes a huge dataset of git commits. Pre-dates LLaMa v2 and Code-LLaMa, so I went to PapersWithCode leaderboards. On HumanEval, it falls a bit below GPT-3.5 and Code-LLaMa. But that's a limited benchmark and there may be more tasks where OctoCoder is more suited. The trick would be to compare these head-to-head, or to notice if there's more support work being done around one (probably Code-LLaMa).
OpenGVLab/OmniQuant
OmniQuant is a simple and powerful quantization technique for LLMs
Project claims a method to quantize even smaller models.
On the Proposed Interstellar Origin of the USG 20140108 Fireball
A critical review of the evidence for the interstellar origin for the USG 20140108 fireball is presented. Examining USG…
More of a paper for "Aliens of Arxiv", but here Canadian and Czech experts are skeptical about Dr. Avi Loeb's claims around extra-hard interstellar meteors.
PMET: Precise Model Editing in a Transformer
Model editing techniques modify a minor proportion of knowledge in Large Language Models (LLMs) at a relatively low…
Team claims to have outperformed ROME and MIMET at editing knowledge inside of a language model. The code is based on MIMET but edits more parts of a model's architecture. Though it's a Chinese research project, they edit knowledge of GPT-J on the existing counterfactual datasets used in the MIMET paper.
"Real Attackers Don't Compute Gradients": Bridging the Gap Between Adversarial ML Research and Practice
Recent years have seen a proliferation of research on adversarial machine learning. Numerous papers demonstrate…
OK, I had to include this one. Thinking about how much of LLM hacking is just people toying around with inputs and prompts, and not using the pixel-level adversarial ML which academia has studied in depth.
Textbooks Are All You Need II: phi-1.5 technical report
We continue the investigation into the power of smaller Transformer-based language models as initiated by…
The sequel to the textbook-trained code model phi-1, this time it's a general language model trained on a corpus of textbook-like text generated by GPT-3.5, and/or filtered web content used to train another model (Falcon).
Training on GPT outputs feels like the long way around for a teacher-student model, no? It's also striking how the paper describes this as "textbooks are all you need" when it's certainly an expensive (if you're not Microsoft or OpenAI) way to get a ton of unverified text.
This work appears to have inspired (on some level) the satire/shitpost paper Pretraining on the Test Set Is All You Need.
The Internal State of an LLM Knows When its Lying
While Large Language Models (LLMs) have shown exceptional performance in various tasks, their (arguably) most prominent…
Researchers train a classifier on values in intermediate hidden layers, to decide if the model's output should be true or false. This greatly improves accuracy of the subject model (OPT, Meta's GPT model). They provide some thoughtful explanations for this process, for example the nature of having generated a token to "commit" the model to completing that thread, rather than measuring loss of the whole answer (I thought this was why decoders can do beam search?); or multiple wordings of the right answer splitting the vote in token-generation