Georeactor Blog
RSS FeedML Arxiv Haul #27
Comments / Criticism
Scriptnotes Podcast had a nice non-technical discussion about AI fears, realism, and career adaptation. https://johnaugust.com/2023/this-uncertain-age
PyTorch release credits influential open source research beyond their own repo https://twitter.com/1littlecoder/status/1730317767205638620
LeCun on conventional LLMs being unable to "think" any more on one token over another at inference time, so any basic filler word is the same level of compute as the answer https://twitter.com/ylecun/status/1728867136049709208
Difficult to find original prompts in papers: https://twitter.com/BlancheMinerva/status/1729229908017086618
HuggingFace now has upvotes and comment threads for Arxiv papers (example: https://huggingface.co/papers/2311.11045) so for 2024 I might try to change up my plan to leaving (positive) comments on papers.
Discussion whether research on "scaling laws" has tapered off https://twitter.com/sarahookr/status/1723784147733258476
WikiANN annotations seem unreliable https://twitter.com/stefan_it_/status/1725307477036507265
Looking back one year at Meta's Galactica launch: https://twitter.com/ylecun/status/1724448825509851332 -> led to -> https://twitter.com/rosstaylor90/status/1724547381092573352
Chat-O.M.G.
Someone added a multi-part question to LangChain examples, which has led to several Q&A generations around the web. Google Search has taken one of these generated answers as truth: https://twitter.com/goodside/status/1723577986538955223
Someone who I follow on Twitter manipulated GPT/DALL-E to generate a character with a lightsaber, and they quote-tweeted this horror show, stop sign anime waifu: https://twitter.com/KatanHya/status/1723781954011586988
Widespread complaints on Reddit that Anthropic's Claude 2.1 release refuses to do more tasks (for example, not generating marketing copy as it would be "hyperbole"). There also was a thread that GPT-4 / Code Interpreter lately is describing or discussing a task, rather than completing the coding/task/transform.
Papers
Adapters: A Unified Library for Parameter-Efficient and Modular Transfer Learning
We introduce Adapters, an open-source library that unifies parameter-efficient and modular transfer learning in large…
The Adapters library was re-launched. I worked with the previous Transformers-based library which attached layers to the end. These days "adapters" makes me think of LoRA-type adapters, and these are included in the architectures.
Can LLMs Keep a Secret? Testing Privacy Implications of Language Models via Contextual Integrity Theory
The interactive use of large language models (LLMs) in AI assistants (at work, home, etc.) introduces a new set of…
Benchmark around LLMs understanding what types of information in a narrative should be kept private, who already knows what information in a semi-private interaction, etc. I think what might be useful here, is that you cannot prompt your way to telling a model to keep private info private, if it's not "aware" of what info that might encompass.
Decoding Intentions: Artificial Intelligence and Costly Signals
This got highlighted during the OpenAI leadership crisis because Helen Toner, then a member of their nonprofit board, is a coauthor. One report was that Sam Altman believed that a board member should discuss the policy/outreach goals of OpenAI, or specific criticisms of OpenAI, through other channels. I read the executive summary: basically it's asking if AI programs have gone beyond safety talk to "costly signals" i.e. commitments, investments.
Anthropic delaying their Claude chatbot and not "productizing" it is praised. I should highlight these two sections on OpenAI:
OpenAI has also drawn criticism for many other safety and ethics issues related to the launches of ChatGPT and GPT-4, including regarding copyright issues, labor conditions for data annotators, and the susceptibility of their products to “jailbreaks” that allow users to bypass safety controls
[on safety / policy] OpenAI’s attempt at signaling may have been drowned out by other, even more conspicuous actions taken by the company
This is really the truth of what criticisms have been thrown at OpenAI, so it may only be people's appearances, or that Toner was reluctant to edit out wording like "conspicuous actions".
Diffusion Model Alignment Using Direct Preference Optimization
Large language models (LLMs) are fine-tuned using human comparison data with Reinforcement Learning from Human Feedback…
RLHF -> DPO. Salesforce/Stanford team got DPO working on SDXL, the diffusion image model.
Emptying the Ocean with a Spoon: Should We Edit Models?
We call into question the recently popularized method of direct model editing as a means of correcting factual errors…
New take for me - skepticism about model editing. I thought that this might challenge the ROME / MIMET / PMET series of editing facts into the model. None are mentioned. Instead they argue how could you possibly update all of the facts which the model could be queried for - the model cannot be continuously updated for all of these situations, and continued pretraining will lead to catastrophic forgetting of old data. Instead they suggest retrieval systems.
FinGPT: Large Generative Models for a Small Language
Large language models (LLMs) excel in many tasks in NLP and beyond, but most open models have very limited coverage of…
Finnish researchers try GPT-3 and continue training HuggingFace's BLOOM model on a mix of its existing corpus plus Finnish. They evaluate it on a new FIN-bench project inspired by BIG-Bench.
https://github.com/TurkuNLP/FIN-bench
First Tragedy, then Parse: History Repeats Itself in the New Era of Large Language Models
Many NLP researchers are experiencing an existential crisis triggered by the astonishing success of ChatGPT and other…
Epic title.
This compares academic NLP's worries in light of dominance of LLMs, to previous upsets in machine translation. I looked for word2vec and BERT in the paper, but technical details of these histories were not so emphasized. Instead it's a call for optimism that academia will continue to follow innovation, hardware will improve and make more models accessible, etc. At Thanksgiving I did talk to someone about how these early BERT models seemed beyond most companies/labs at first, but now are tiny compared to the models that we work with now.
GAIA: a benchmark for General AI Assistants
We introduce GAIA, a benchmark for General AI Assistants that, if solved, would represent a milestone in AI research…
I saw this Meta/HuggingFace paper on Twitter and on my Google Scholar notifications (due to BIG-Bench) so already showing up a lot on my screen.
The authors have come up with several assistant tasks which GPT-4 with plugins still struggles to accomplish. The GAIA questions have levels which are decided by the number of individual steps / retrievals / analyses / image-reads needed to solve a problem (figure 1 has some examples). After seeing the advanced problems, I was genuinely surprised that the humans committed to solving the problem enough to average at 92% success rate (they recruited some annotators to develop and validate the questions were answerable, and paid human "annotators" from Surge AI to evaluate).
Unexpectedly the "AutoGPT" retrieval-store-query-loop system underperforms.
There's an interesting section about continuation of the GAIA benchmark, when this data might become available in training corpora, or if online data sources will disappear or add robots.txt to forbid GPT agents.
Ghostbuster: Detecting Text Ghostwritten by Large Language Models
We introduce Ghostbuster, a state-of-the-art system for detecting AI-generated text. Our method works by passing…
I think we decided that you can't auto-detect AI-generated text, but here we are. Authors at UC Berkeley collect text from the WritingPrompts subreddit (going pre-ChatGPT launch) and "IvyPanda" student essay dataset. Results are better than GPTZero and other extant tools.
Wanted to share a seemingly straightforward diagram from the paper:
Giant genes are rare but implicated in cell wall degradation by predatory bacteria
Across the tree of life, gene lengths vary, but most are no more than a few thousand base pairs in length. The largest…
Throwing a biology paper in here. Each gene in a DNA strand contains exons (which code for amino acids of a protein) and introns (which do not join the RNA product). The definition of this is sketchier than undergrad bio would suggest (alternative splicing can code different proteins from a gene).
Anyway they went searching for "giant" genes in biology, measured in base-pairs from start to finish, and they found these cell wall proteins in bacteria. Some of these are truly giant 80k amino acid proteins (almost 3x previous discussed largest) where it's challenging to predict the folding/structure. I was thinking a big chunk of giant genes would be repeated copy errors or giant intron sections, and that's not supported by the paper. Instead these seem to be old core code for bacteria.
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
We present GPQA, a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics…
Mostly-NYU authors rolling out a new benchmark which are challenging for GPT-4 and other top LLMs. Interestingly the team uses the BIG-Bench "canary string" with an additional code for them to filter out both for GPQA.
The multiple choices are designed by experts in natural sciences, other experts agree in answers, and then non-expert humans are shown to do poorly on the question (they say: ≤ 1/3 correct, even when allowing Google searches, for "Diamond" level questions).
The questions seemed direct after so many Chain-of-Thought papers, but further reading shows they got question-writers to write up some things which they could use for few-shot Chain-of-Thought.
Above all, this spells out a great method for collecting challenging, validated questions without trolling the same internet corpus as the LLMs.
Instruct2Attack: Language-Guided Semantic Adversarial Attacks
We propose Instruct2Attack (I2A), a language-guided semantic attack that generates semantically meaningful…
By now you've probably heard about how image models confuse horses and zebras, or dogs and wolves, based on the ground / grass around them. The team uses a diffusion model to edit the images, and text suggestions from GPT-4 (such as: "place it in a rainforest"), to obfuscate the images to ImageNet classifiers.
I find "a language-guided semantic attack" phrasing to be incomprehensible; you've done something cool here, and for a while I was trying to understand if that means "prompt engineering" or what.
Making AI Less "Thirsty": Uncovering and Addressing the Secret Water Footprint of AI Models
The growing carbon footprint of artificial intelligence (AI) models, especially large ones such as GPT-3, has been…
Measuring "water footprint" of model training. Loss to cooling systems can be measured in a couple of different ways: withdrawal from the system, and consumption by evaporation / steam.
Green energy proponents might want a data center to be built in a warm, sunny climate to maximize benefit of solar energy. But water efficiency would prefer a cooler climate.
These calculations avoid hydroelectric uses of water, which is a part of why data centers and Bitcoin miners get located in some regions.
optimistix
Nonlinear optimisation (root-finding, least squares, ...) in JAX+Equinox.
Fun with optimizers, but for nonlinear functions and the JAX base framework.
Equinox is a new-ish framework on top of JAX (similar to the Flax/Haiku) with both libraries being built by Patrick Kidger at Google X.
Orca 2: Teaching Small Language Models How to Reason
Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned…
Microsoft Research successor to the original Orca model. There are a handful of models which were based on that paper and code (I forget some details of why OpenOrca was created for license or content issues?). On review, one of the benefits of that paper was the ability to pretrain on high-quality synthetic / generated text.
Here we get a return of synthetic text. Surprisingly there is no safety RLHF stage. The model is shown how to answer questions using a variety of techniques:
(step-by-step, recall then generate, recall-reason-generate, direct answer, etc.)
Othello is Solved
The game of Othello is one of the world's most complex and popular games that has yet to be computationally solved…
Using an alpha-beta algorithm to find perfect play of Othello leads to a draw. There is one author, so this looks like a pet project! Hacker News put some emphasis on the game being "weakly solved" which I think means that they found a particular route of play which cannot be defeated, but they could not step in and solve any game of Othello to its best conclusion.
Prompt2Model: Generating Deployable Models from Natural Language Instructions
Large language models (LLMs) enable system builders today to create competent NLP systems through prompting, where they…
Automating the process of selecting a model and dataset to build a custom finetuned model. The input prompt is read by GPT-3.5 Turbo, and possibly translated by DeepL.
Skill-Mix: a Flexible and Expandable Family of Evaluations for AI models
With LLMs shifting their role from statistical modeling of language to serving as general-purpose AI agents, how should…
Princeton/DeepMind launch of this evaluation which tries to disprove that LLMs are "stochastic parrots". The system generates challenging writing prompts for the model - picking a topic, and a requiring the response to have a complex set of 101 skills (rhetorical devices such as red herring, metaphor; plus some science-y stuff such as "spatial reasoning").
These create sentences not found in online corpora, and remind me of the GPT-4 "respond with first letter of each word in alphabetic order" type questions which would be really challenging for me as a human (in fact the paper says humans had trouble grading, so that's left to LLaMa and GPT). The rhetorical devices brought me back to a sophomore English class where we had to memorize terms like "litotes" which I never heard of again.
Of LLaMa, GPT, and some others (Falcon, Mistral), GPT-4 is the only one to get appreciable scores at 5-6 skills. LLaMa is scalably better from 7B to 70B params on 2 skills, but none do well on 3+ skills, unless grading by another LLaMa model.
SuperTweetEval: A Challenging, Unified and Heterogeneous Benchmark for Social Media NLP Research
Despite its relevance, the maturity of NLP for social media pales in comparison with general-purpose models, metrics…
Cardiff NLP, which I'm aware of through their popular Twitter models (based on download numbers), releases a benchmark of Tweet-related tasks so we can remember the era where you could mention Twitter in polite society. These are all classic NLP tasks (hate speech, NER, similarity, emotions).
GPT-3.5 did the best, but Flan-T5 models were bolded in the results.
We refrained from highlighting ChatGPT results due to its closed and irreproducible nature, as well as the possibility to have been directly trained on some of the test sets.
Neat!
The Gates Foundation’s new AI initiative: attempting to leapfrog global health inequalities?
The Bill & Melinda Gates Foundation has long been criticised for championing the trend of socially reductive, 'magic…
Editorial in BMJ Global Health, a call to action to reject the Gates Foundation's call for LLMs in their research and global health work. The writers are concerned about colonial mindset / bias. They also touch on a particularly underexplored part of AI replacing civil jobs and roles - if your medical providers and schools and public defenders are lacking resources, is AI going to help fill that gap, or is it giving up on the problem for efficiency?
What Makes it Ok to Set a Fire? Iterative Self-distillation of Contexts and Rationales for Disambiguating Defeasible Social and Moral Situations
Moral or ethical judgments rely heavily on the specific contexts in which they occur. Understanding varying shades of…
We all know the example of "shouting fire in a crowded theater". LLMs have not advanced to this level, but instead we're seeing understanding of acceptable contexts (you might set a fire at a BBQ). For reasons which aren't super-clear to me, they use multiple models (GPT-3, DeBERTa) to create or filter the initial dataset of examples. The student model is based on Flan-T5.
Introduced me to the paper The political ideology of conversational AI: Converging evidence on ChatGPT's pro-environmental, left-libertarian orientation
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs
Methods for finetuning generative models for concept-driven personalization generally achieve strong results for…
Hot off the presses, multi-LoRAs so hot right now. Here the focus is on image diffusion adapters. Google and UIUC researchers cite multiple examples in informal media about trying to combine or train multiple LoRAs together (for example combining dog-adapter and sketch-adapter to produce sketches of dogs). The Zip method can be applied after the fact and has superior results.
The bulk of the paper is describing how the different weights are smoothed over to merge, which I feel is summarized here:
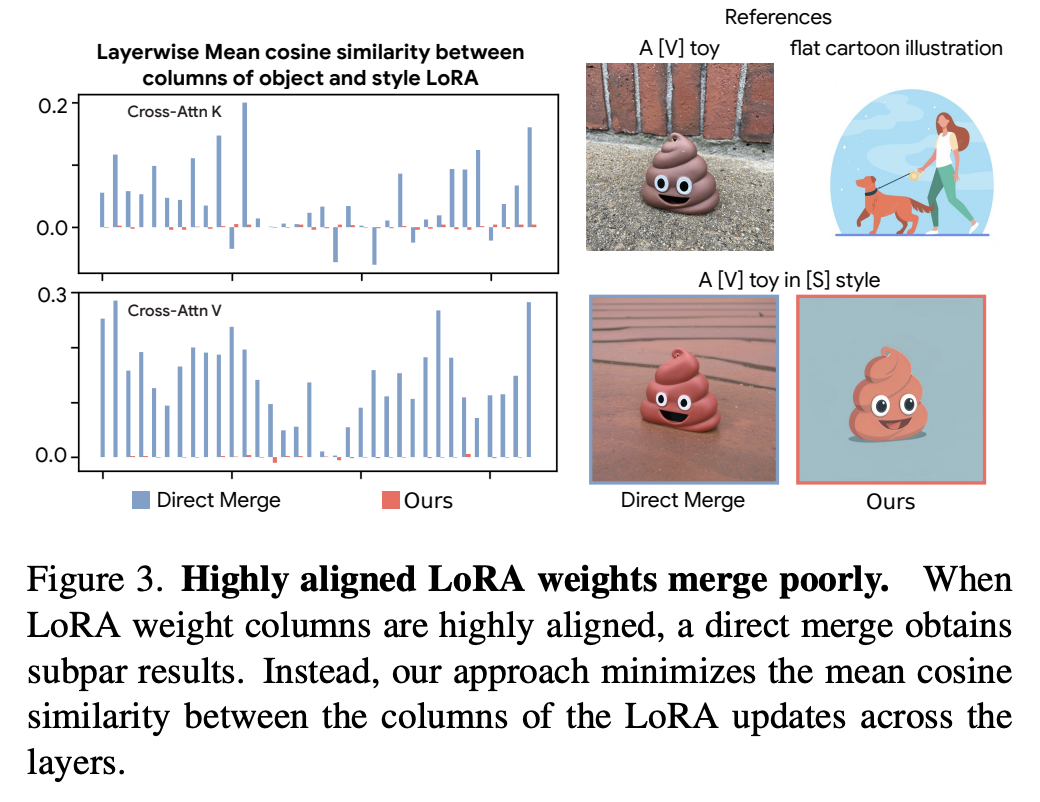
The paper doesn't include code, but someone at Stability AI set up unofficial code over at https://github.com/mkshing/ziplora-pytorch